


Visual Sprint Planner is a Jira Cloud plugin allowing to visualize the sprint planning process. The initial version was deployed on Kubernetes Service, simply K8s managed by IBM. We have to choose a desired K8s version, a few parameters, and the number of worker nodes. Basic stuff. In addition to the quick creation of the cluster itself, a positive surprise was also the possibility of creating a complete CI/CD pipeline very easily, so we can deploy apps on a newly created cluster. Here are a few of the possibilities:
After a while, in addition to CI/CD, the package included: a task management tool, GIT repository with sample code of a containerized application, and a web IDE:
The additional DevOps Insights item is a set of predefined metrics, statistics, and trends presented on dashboards. Everything in the context of our new pipeline:
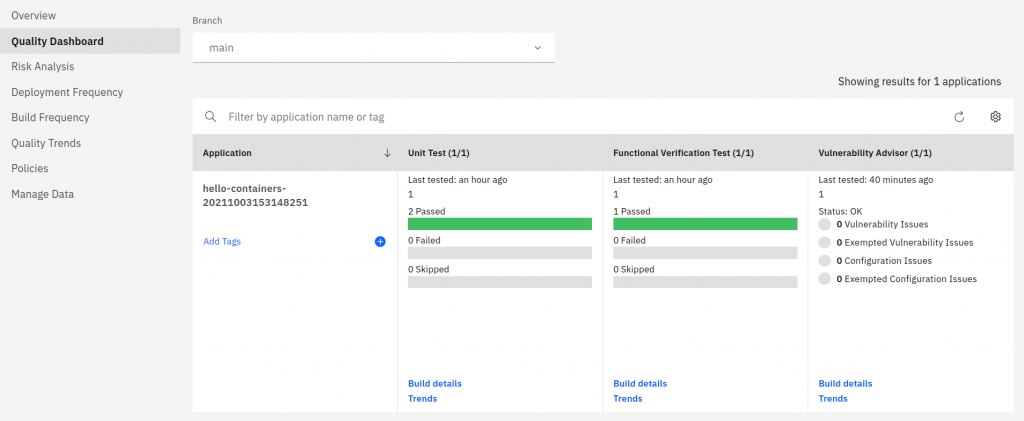
This was not the end of pleasant surprises!
The individual steps of the CI/CD process included steps such as code tests at the stage of its building and even tests of security vulnerabilities in the image (!) at the containerization stage:
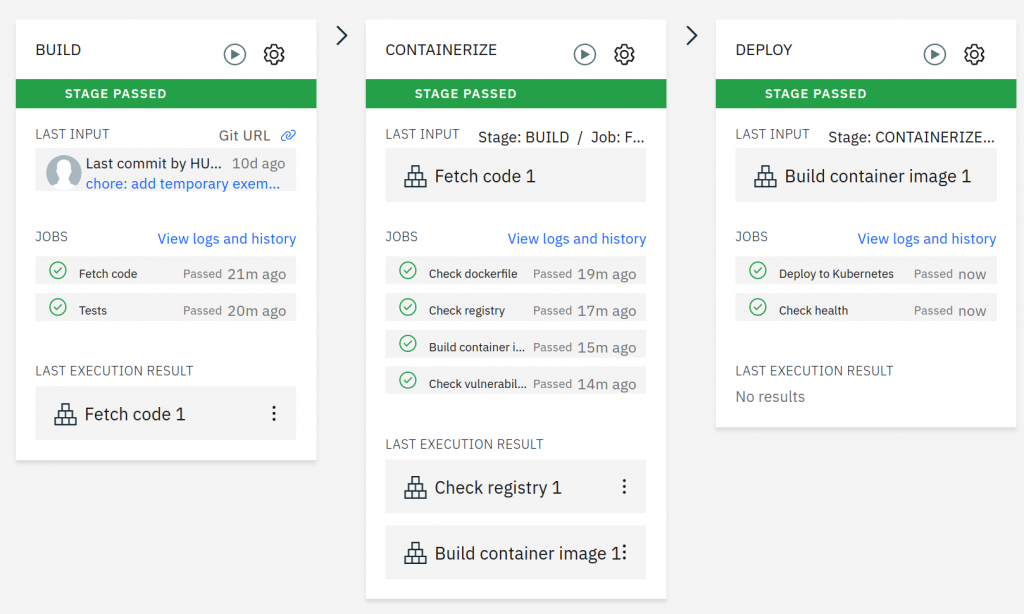
It’s all turned on by default, integrated, trial-tested, and ready for further use. We can put our own code in the repo and deploy the application. The programmers were very satisfied already. Wow!
The next (and last) step enabled communication between Atlassian Cloud and the Visual Sprint Planner backend. This required the installation of a trusted certificate. We have successfully used a certificate from Let’s Encrypt installed on the K8s cluster here.
But don’t count your chickens before they hatch. During the application tests, a failure occurred, which resulted in the lack of access to the DNS service from the pods. Specialists from IBM Poland were engaged to analyze the problem. During the diagnostics, it turned out that we are dealing with a failure of a wider range and affecting the region we use (Frankfurt). When it was fixed everything started to function properly.
After a month, we verified the cost of operating the K8s clusters against the resources required by the applications. We decided to migrate towards a fully serverless solution. The service that allowed the container to run in this mode was called IBM Cloud Code Engine. It will enable you to allocate very low values of vCPU and memory, so you pay only for the resources used, gaining great operational convenience. It is not a classic FaaS service (Cloud Functions in the IBM cloud), so we have no time limit for our code execution. The current configuration of the Visual Sprint Planner test and production environment:
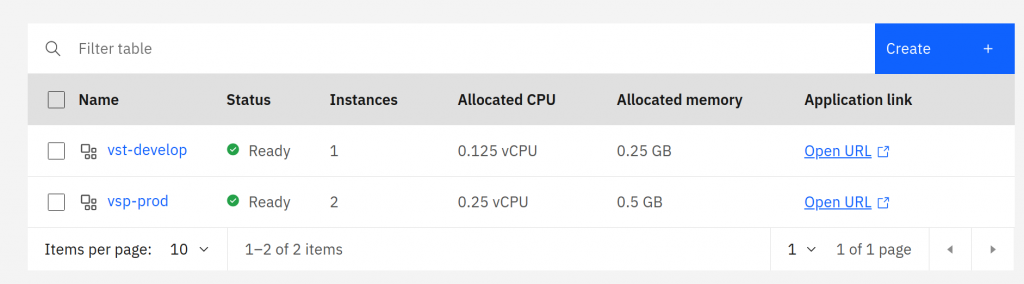
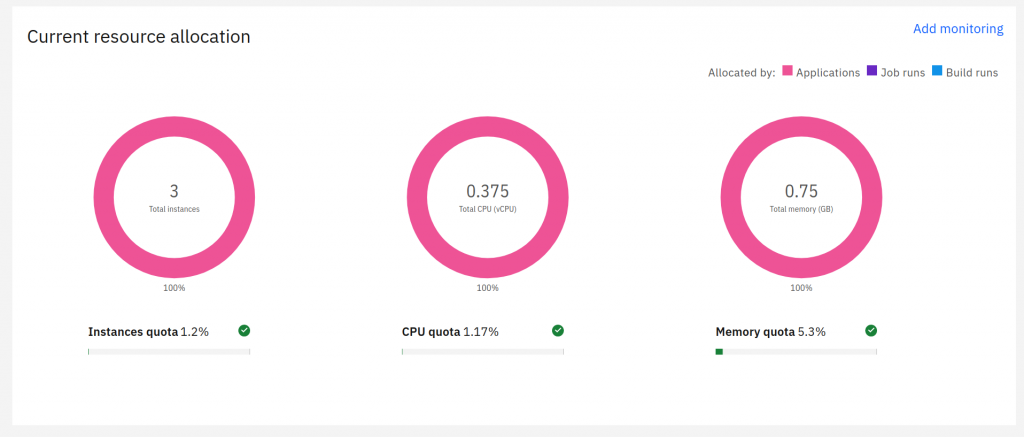
The application has been working without any problems for several months in the current architecture. It should be mentioned that the migration to Code Engine did not require any changes to the code of the application itself. It worked without surprises. Management is also much simpler than in the case of the K8s cluster. According to the current needs, it comes down to specifying the minimum and the maximum number of instances selected automatically during work.
Thanks to the transition to Code Engine, we have reduced the costs related to maintenance by order of magnitude.
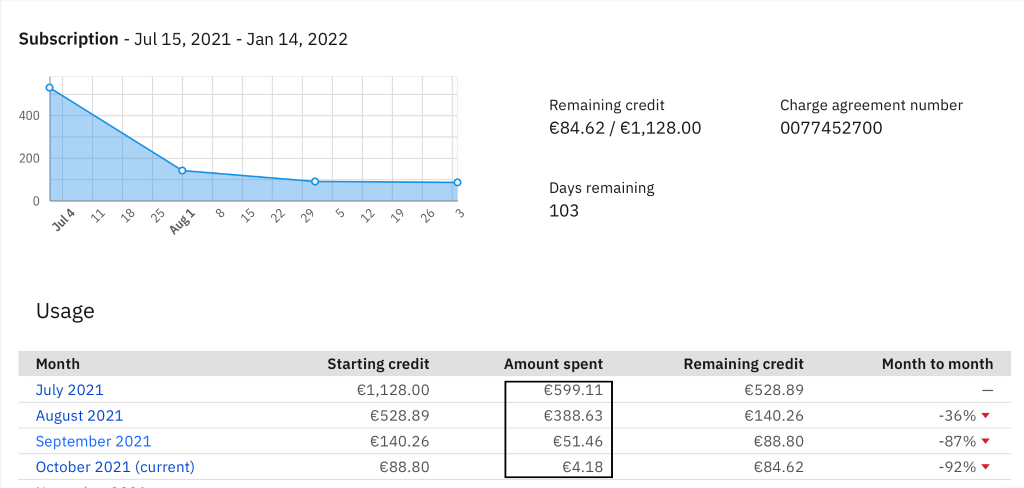
The first month on the platform was a surprise. 599€ for a cluster with two nodes? A bit much. This, among other things, got us to look for new solutions. Replatforming the application brings significant savings. Currently, the platform costs us around 52€, whereas the MognoDB maintenance costs are the highest. So it was possible to reduce the running costs by a factor of ten.
An additional advantage of using the Code Engine is that you do not need an administrator who makes sure that the entire cluster works as it should. Administrative activities are limited to checking if the platform is working.
Finally, we have to admit that IBM did its best, and even small companies like ours today can find their place on IBM Cloud.
Julian Jelinski
Content and marketing manager and a public speaker. I write fluffy, entertaining pieces and detailed case studies. I’m enamored with the fascinating world of technology and digital transformation.



![What can we learn about iterative project planning from space travel? [Part 3]](https://hobly.pl/wp-content/uploads/2022/07/1635153553791-980x513.png)
![What can we learn about iterative project planning from space travel? [Part 2]](https://hobly.pl/wp-content/uploads/2022/07/1634553241541-980x513.png)
